


作者:苏扬
美国实施的芯片出口管制正在对英伟达造成持续冲击。
数据显示,今年前两个季度,英伟达在中国市场的损失预计达到 125 亿美元,其市场占有率也从巅峰时期的95%大幅下跌至目前的50%。
英伟达CEO黄仁勋反复强调中国市场的战略价值,表面上是因为营收和市场份额的考量,深层原因则是其绝对市场主导地位正在受到挑战——中国本土芯片厂商的快速成长正在打破原有格局。
在H20出口许可迟迟无法兑现的情况下,英伟达计划于7月份推出应对方案,通过减配、“阉割”的形式绕过出口管制,由B20、B40/B30来替代H20,试图重新夺回市场份额,以扭转在华业务的下滑趋势。
特朗普此前在社交平台上称,会尽快向英伟达发许可证
6月中旬,本营国际(AceCamp)公开了一份专家调研纪要,称英伟达预计7月份针对中国市场推出 H20 继任者 B20 和 B40/B30 芯片,单卡售价6500美元~8000美元,服务器预计80000美元~100000美元之间。
本营国际在该纪要中指出,新的B20、B40/B30基于GB202 GPU,该GPU曾用于消费级的RTX 5090和专业级的RTX Pro 6000保持一致。内存采用了GDDR7 ,分为 24GB、36GB、48GB 等版本。互联方面,B20通过NVLink总线连接到CX-8芯片,形成一个相当于PCIe卡的离散模块,以实现PCIe互联,带宽 800Gbps,即100GB/s,适合 8-16 卡小规模集群的推理和小模型后训练;B40/B30 直接支持 NVLink 互联,带宽900GB/s,采用OAM 形态,可用于 NVL72 等高密度集群,但受计算性能和带宽限制,集群性能不及 H20(~85%)。
黄仁勋手握一把手术刀,小心切割 GPU,图片由AI生成

第三代中国“特供”
大厂买B40、平价IDC选B20
受美国出口管制动态调整的影响,英伟达过去几年持续不断地调整产品SKU,以应对禁令。
如果B20按期上市,将成为第三代中国“特供产品”,前两代分别是基于Hopper架构的H20、H800以及Ampere架构的A800。
相比上一代的H20,这代产品取消了HBM高带宽内存,内存带宽从4.8TB/s(HBM3e版,HBM3版为4.0TB/s),下滑至1.5TB/s-1.7TB/s,直接影响就是支持的并发数减少。
GDDR7替换HBM是出于合规需要,与美国商务部的出口管制条例更新有关。2024年,美国商务部将HBM内存定义为先进计算和人工智能应用的存储器进行特殊管控,其要求内存带宽密度在每平方毫米2GB/s及以上的 HBM 产品,其出口、再出口均受管制,覆盖HBM2、HBM2e及更先进的产品。
尽管内存缩水属于被动调整,但GDDR7应该是现阶段避开管制线的最优选择。千芯董事长陈巍指出,“GDDR7带宽预期可以超过1.5TB/s,虽不如HBM3e,但一般比A100的HBM2e的表现更好,可视为4090的IDC版。”
对于改配GGDR7的B20芯片,一位资深国产GPU从业者则给出相反的评价,“算力有点低,内存大小和带宽都上不去,性能弱于国产头部。”
相比之下,英伟达B40/B30在国内市场可能更受关注,关键在于它保持了与H20相同的NVLink互联功能,最大带宽可达900GB/s。上述国产GPU从业者解释:“通过NVLink可以实现Scale Up扩展,像NVL72、NVL144等,类似华为Cloudmatrix 384的架构。”
作为特供中国的版本,每次在上市初期都会引发质疑,H20和H800都经历过这个阶段,但最终由于客户可选择的替代方案有限,随着产品供应逐渐稳定,质疑声逐渐消退,“真香定律”开始发挥作用——一些企业甚至通过大批量采购,跻身英伟达全球前五大客户行列。
2024年12月,金融时报援引市场机构Omdia的数据称,微软2024年总计采购了48.5万张英伟达Hopper芯片,字节跳动凭借23万张位列第二。今年4月份,路透社报道称,包括字节、阿里在内的中国科技公司于今年一季度总计采购了超过160亿美元的H20芯片,折合人民币超过1160亿元。
一位大厂算法工程师表示,“B40(性能)应该不如H20,价格上也是这个定位,作为选择不多可以买的卡,还是有需求的。”
陈巍认为,基于目前的消息判断,在B20、B40/B30的选择上,不同客户会存在不同的倾向,“B20组网的有效带宽低于B40/B30,考虑到模型大小变大的趋势,B40/B30会是有钱大厂的选择,平价IDC厂可能倾向于B20。”
英伟达的焦虑、国产的难题
黄仁勋和整个硅谷都在焦虑,强调过度管制会影响美国芯片的竞争力,给来自中国本土的竞争对手创造机会,其市场份额从95%,下滑至50%是一个非常直观的量化指标。
受特供版芯片硬件芯片不断缩水的影响,上述国产GPU从业者透露,一些大厂在综合权衡之后,已经在加速陪跑国产生态,“如果考虑今后的供应安全和供应稳定,一定要尽早导入国产,但目前企业对英伟达的供应都还抱有一定侥幸。”
在他看来,企业在国产生态门外徘徊,与切换国产生态所需要的额外成本、业务落地速度有关,“本来好好地采用英伟达方案,导入(国产)新方案可能带来额外投入,还不见得有太多额外收益,就可能有顾虑。”
英伟达的产品性能缩水给国产带来机会,但国产也有自己的难题。
上述大厂算法工程师表示,“国产卡算力还是可以的,就是生态和集群还有些地方需要进步。”
英伟达的生态,核心关键词即CUDA,它提供了统一的编程模型、丰富的代码库,对英伟达的硬件体系、主流的AI框架,都具有良好的兼容性,开发者容易对其形成依赖。目前,国产GPU基本都在推动对CUDA生态的兼容,帮助开发者迁移。
“NV的生态垄断还在,”陈巍说,但他认为国产中高端GPU的挑战还包括先进工艺产能。
根据公开资料,目前国产GPU的工艺制程的上限为7nm,受禁令的影响,自去年台积电自查事件开始,其已经无法为大陆客户的7nm AI芯片提供代工服务。
“中高端国产卡短期受限于工艺和产能,最近连EDA工具都有波动。”陈巍说。
EDA工具的波动则与日前新思科技、楷登电子、西门子三大巨头暂停对中国大陆供应的传闻有关。作为“芯片之母”,EDA软件不仅用于半导体设计,也广泛用于晶圆制造、封装测试的多个环节,包括良率预测、信号分析等,如果上述环节的EDA工具管制收紧,也会影响到国产GPU的产能。
算力的A、B面
数字石油、吞金兽
一台8卡B40/B30服务器,单价预计在10万美元左右(约合人民币70万元),由于支持NVL72拓展,构建一台B40 NVL72机柜,硬件成本将超过人民币600万元。
“B40的TCO(总拥有成本)跟H20差不多,吸引力不高了。”上述国产GPU从业者表示。
H20作为特供中国的上一代芯片,今年初受DeepSeek热潮的推动,一度受到互联网公司、金融机构的疯抢,“8卡H20服务器价格,一路从88万元涨到了105万元,由于成本低、合规,大厂都是成千台的采购。”一位GPU分销商此前透露。
如果按服务器运行状态分,不管是B40的70万元,还是H20的88万元,都属于静态成本,一旦开机运行,伴随巨大尖锐刺耳的轰鸣声而来的,还有高昂的动态成本。
一台B40 NVL72机柜机的动态成本,按费用项目拆分涉及质保、运维、软件授权、能耗等,预计在700万元以上。仅电费一项,按单机柜能耗50千瓦来预估(对标H20单卡400瓦+CPU+交换机等硬件功耗),每年的能耗就接近44万度,按一度电1元的均价算,就达到44万元。
静态成本+动态成本,按年合计接近1300万元,平均到每天的成本超过3.6万元,假设B40的算力能达到H20的85%,后者单卡FP16算力为0.148P,B40 NVL72的总算力大概在9P左右。
年成本1300万元对应的还仅仅是B40 NVL72这类算力受限的方案,如果更换成H100,静态+动态成本将大幅飙升。
按此前ServeTheHome披露的信息,马斯克旗下Colossus AI超算集群采用超微基于HGX H100服务器定制的机柜,单个服务器容纳8张H100 GPU,每个机柜可容纳8个服务器,总计64张H100 GPU,可以提供64P的FP16算力,其静态的硬件成本即超过2000万元。
以此来算,硅谷巨头们频繁提及的万卡H100集群,静态成本就超过30亿元,堪称硅基时代的吞金兽。
高昂的成本让算力更趋向于科技巨头们的游戏,一些院校、科研机构和初创企业则很难构建大规模的自有算力体系。
今年的智源大会上,智源研究院理事长黄铁军教授透露,“现在学校没有那么多算力,百卡可能都没有,学生们没有那么多实践的机会,智源虽然有一定的算力,但也只有1000P,千卡级别,这个资源和一个大模型公司比还差很多。”
黄铁军说,“智算平台建设起来之后,给学校、给这些人才更多基础资源条件,特别重要。这跟物理、化学、生命前沿研究一样,没有尖端的仪器,很多工作没法开展。”
谁会背着硬盘出海?
中国市场上的智算中心建设如火如荼,但先进算力仍然面临出口管制,企业开始尝试在海外训练大模型以提升效率。
日前,华尔街日报报道称,一家中企利用海外分部租赁当地服务商300台服务器,安排工程师通过硬盘转运4800TB的企业数据到海外进行模型训练。
利用子公司/海外分部/关联公司等租赁当地算力训练模型示意图 来源:WSJ
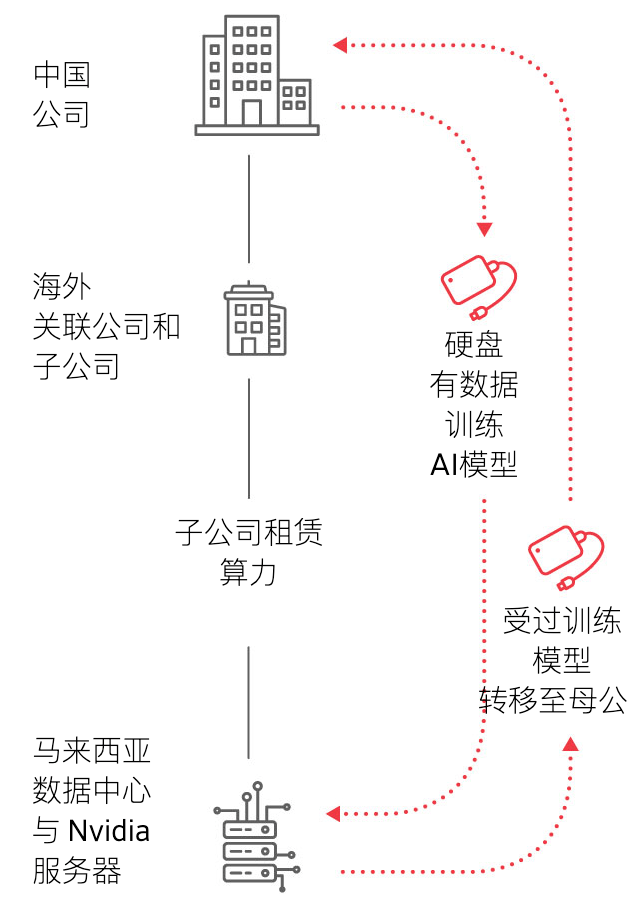
利用企业数据训练自有模型技术上可行,但这种行为是否会触及美国的出口管制条例?
2024年早期,拜登政府曾讨论过要评估实施限制,阻止中国企业获取美国云计算服务,但最终并未推行,而特朗普政府于今年5月份在废除“AI扩散规则”时,在新闻稿中明确提及,如果IaaS(基础设施即服务)提供商知晓客户在AI模型训练且用途敏感需要申请许可证。换句话说,只要训练模型不用于敏感用途,即属于合规范畴。
“这个风险目前主要限制军事相关的模型训练,一般民用的不受限制。”一位合规领域从业者表示。
租赁海外云厂提供的先进算力需要合规支撑,而中国企业的数据出境也同样需要做合规。
北京丰礼律师事务所合伙人刘星认为,就华尔街日报报道的案例来看,企业携带自有数据出境行为并不违法,“特定数据出境需申报安全评估,如不涉及“重要数据”和个人信息,一般不会触发评估要求。”上述合规领域从业者也认同这种说法,在他看来,企业按照法规要求做好脱敏即不构成隐私和敏感数据。
“基因数据、测绘数据、出口管制的技术数据、安防数据等都属于重要数据。”刘星补充道。
利用海外算力训练大模型这种路径,虽然技术、法规上都存在可行性,但实际能匹配到的业务场景有限。
“目前大模型训练这波演进趋势,都是主要的几个大玩家在玩(没有使用海外算力的需求),智驾算法训练现在虽然在卷,但使用海外的CSP,像AWS、Azure这种,折腾的风险太大,即便是走合规路径出海,操作上也不具备可行性。”上述国产GPU从业者表示。
刘星认为,互联网大厂很多都是“关键信息基础设施运营者”,符合《数据出境安全评估办法》规定的申报情形,“国家管理更严格,大厂做(出海训练模型)这类事估计会更谨慎。”
而在陈巍看来,携带数据出海做模型训练,好处是可以接触到更先进算力,数据不走互联网,一般不需要担心数据泄露的风险,更适合做行业大模型的中小厂。
“原文写得是300台,初步猜测是H100,大概2400卡的规模,”陈巍说,“DeepSeek就是用2048卡训练的,而大厂可能会用万卡集群做训练。”
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






